
앞선 콘텐츠를 통해 스테이블 디퓨전을 사용하는 데 있어 별도로 학습된 체크포인트 모델을 다운 받고, 세팅하는 것의 중요성에 대해 알아보았습니다.
지난 콘텐츠 확인하기
이번에는 그러한 스테이블 디퓨전을 사용할 수 있도록, 노드 베이스의 인터페이스를 제공하는 ComfyUI 필수 노드에 대해 말씀드려볼까 합니다. 이는 스테이블 디퓨전과 ComfyUI를 통해 이미지를 생성할 때 반드시 이해하고 있어야 하는 부분이라 생각합니다. 그럼 천천히 설명을 드려보도록 하겠습니다.
ComfyUI 필수 노드와 특징
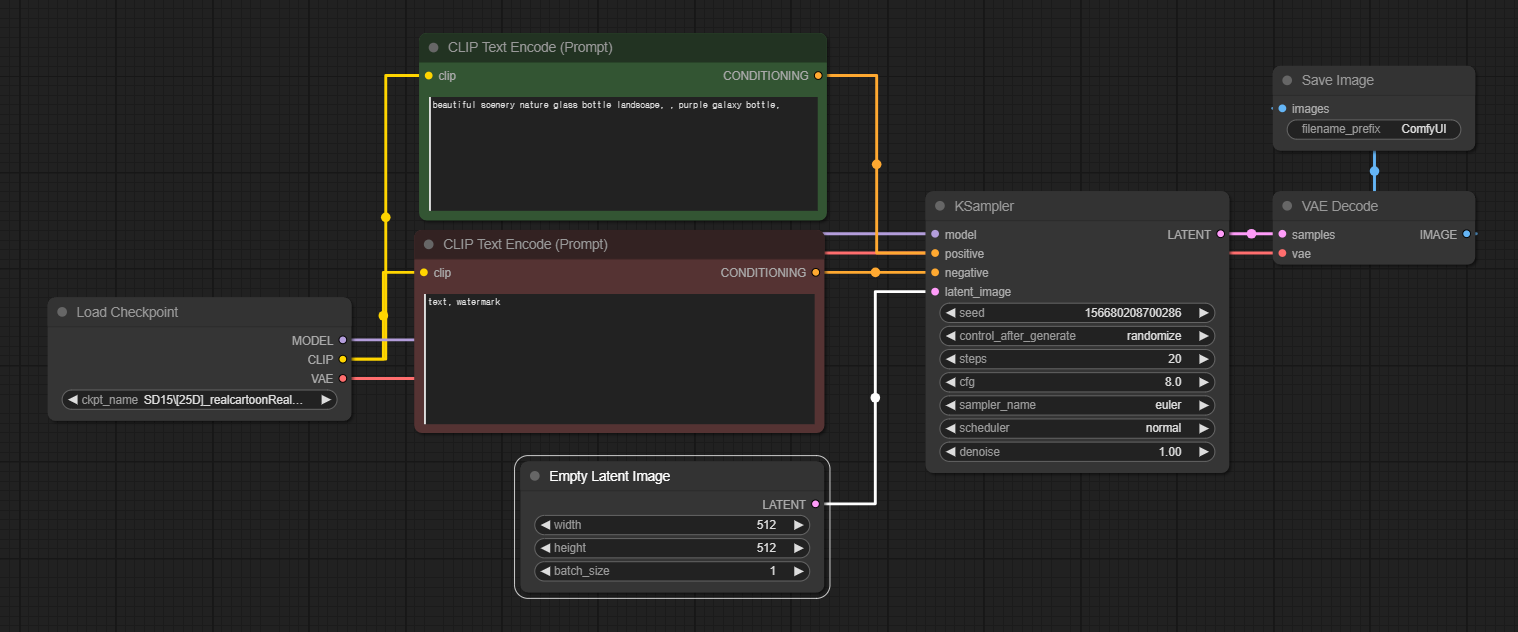
ComfyUI에서 이미지를 생성하기 위해서는 반드시 다음의 핵심 노드를 연결해야 합니다.
[ Load Checkpoint ]
[ CLIP Text Encode ]
[ Empty Latent Image ]
[ Ksampler ]
[ VAE Decode ]
I2I(Image to Image, 이하 I2I) 이미지 생성의 경우 [ VAE Encode ] 노드 또한 필요하지만, 이번 콘텐츠에서는 T2I(Text to Image, 이하 T2I) 이미지 생성에 기반하여 설명 드리겠습니다.
1. Load Checkpoint
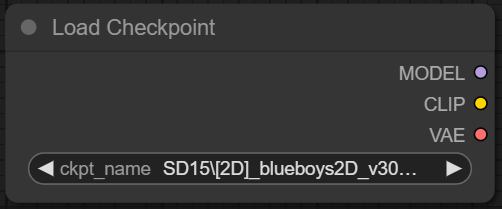
Load Checkpoint 노드의 경우 말 그래도 사전에 받아둔 스테이블 디퓨전 체크포인트 모델을 로드하는 역할입니다. ComfyUI를 활용한 이미지 생성 시, 가장 기반이 되는 노드라 말할 수 있으며 Model, Clip, VAE 총 3가지의 출력 단자를 가지고 있습니다. 모델이 학습한 데이터가 3가지 단자를 통해 연결된 각각의 노드에 전달하게 되면서 원하는 이미지가 생성되는 것입니다.
2. CLIP Text Encode
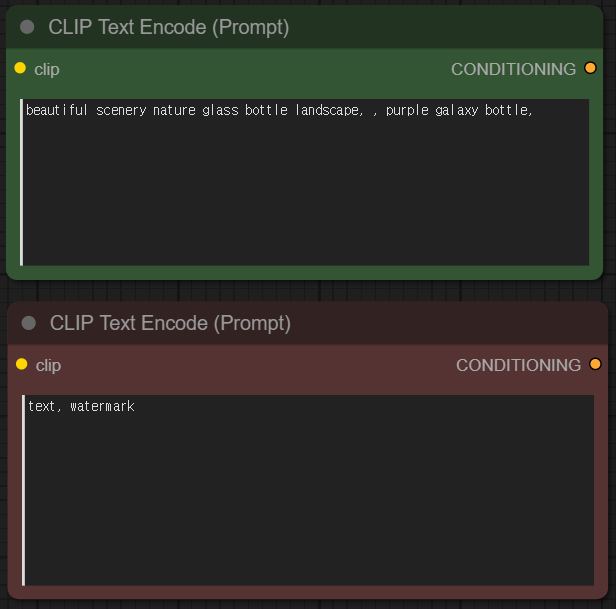
CLIP Text Encode 노드는 유저의 텍스트 프롬프트를 인코딩하여 모델이 이해할 수 있는 형태로 변환시키는 역할을 담당합니다. 보통 긍정 프롬프트, 부정 프롬프트 두 가지 구분해 사용하며, 체크포인트 모델과 연결되며 이미지를 생성시키기 위한 특정 조건을 설정하게 됩니다. 이후 Ksampler 노드의 Positive, Negative 입력 단자를 활성화시킵니다.
*Conditioning 개념 확인하기
3. Empty Latent Image
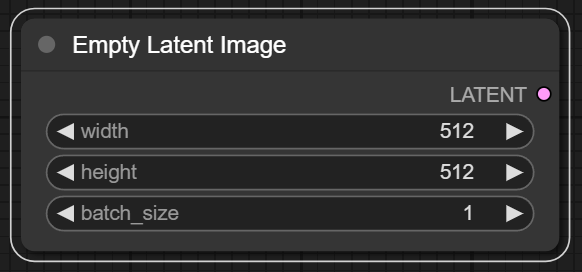
Empty Latent Image 노드는 말 그대로 빈 잠재 공간을 생성해 주는 역할을 합니다. 여기서 말하는 잠재 공간이란 모델과 컨디셔닝에 맞추어 이미지를 생성하는 캔버스이라고 할 수 있으며, Width와 Height 수치 조정을 통해 사이즈를 변경할 수 있습니다. 여기서 주의해야 할 점은 사이즈 조정 시 8의 배수여야 한다는 것이며, 예컨대 Width "512"에서 "516"이 아닌 "520"으로 조정하여 이미지 생성하는 것을 권장하는 바입니다.

그리고 가장 중요한 것은 처음부터 너무 큰 사이즈로 이미지를 생성하는 것은 지양하시기 바랍니다. 보통의 모델인 경우, 이미지 학습 시 작은 사이즈로 학습한 경우가 대부분이기 때문에 너무 큰 Latent Image 사이즈를 사용하게 될 시, 상기 이미지와 같이 특징이 반복되어 출력되거나 전체적 일관성 이 떨어질 수 있습니다.
SD1.5 모델 추천 사이즈
정방형 : 512*512 or 768*768
가로형 : 768*512
세로형 : 512*768
SDXL 모델 추천 사이즈
정방형 : 1024*1024
가로형 : 1152*896
세로형 : 896*1152
4. KSampler
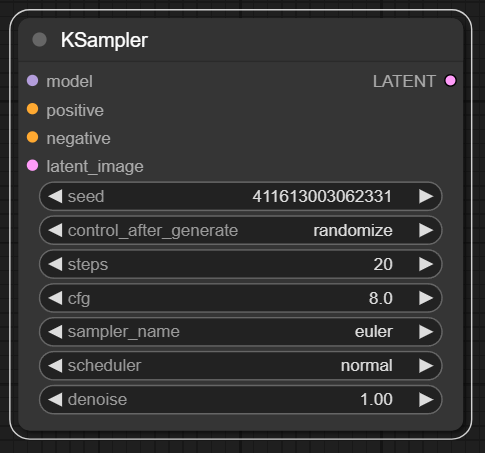
지금까지의 노드와 달리 Ksampler는 입력 단자와 출력 단자 모두를 가지고 있습니다. 특히 왼쪽에 입력 단자들이 집중된 것을 확인해 볼 수 있습니다. 그 이유는 Ksampler 노드를 통해 모델 정보, 프롬프트(컨디셔닝), 사이즈 등의 여러 정보를 취합하여 실질적인 이미지 생성 과정이 시작되기 때문입니다. 그만큼 중요하기 때문에 다양한 파라미터를 가지고 있습니다. 천천히 하나씩 설명드리겠습니다.
(1). Seed
Seed는 스테이블 디퓨전에서 이미지 생성 과정의 시작점을 결정하는 중요한 숫자 정보입니다. 이미지 생성 시 랜덤하게 부여되는 값으로서 동일한 조건의 정보가 입력되었다고 하더라도 만일 Seed 값이 다르다면 이미지 결과 또한 다르게 생성됩니다. 그런데 달리 생각해 보면 특정 생성 이미지의 Seed 정보를 알고 있다면, 얼마든지 같은 결과물을 다시 재현할 수 있다는 것을 의미합니다. Seed의 경우 랜덤하게 부여하거나 직접 숫자를 입력할 수 있습니다.
(2). Steps
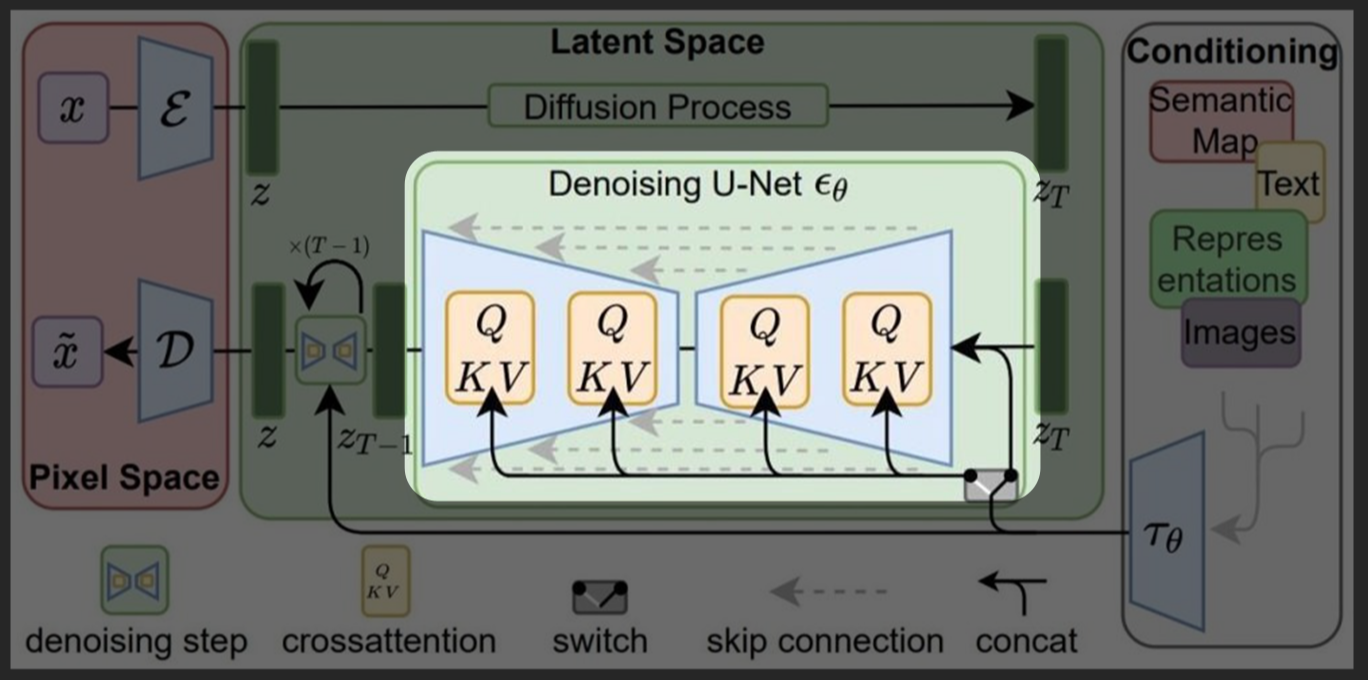
Step에 대한 개념을 이해하기 위해서는 다시 조금(?) 어려운 구조에 대한 이해가 필요합니다. 스테이블 디퓨전 모델의 이미지 생성 메커니즘에서 제일 중요한 개념은 바로 Noise와 Denoise입니다. 학습 모델과 컨디셔닝에 의해 이미지 Noise가 예측되고 Denosing 되면서 이미지가 생성되는 것입니다. 이러한 과정이 일어난 곳을 U-net이라 부르며 이곳에서 몇 번의 Denoising 과정을 거칠 것인가 결정하는 것이 Step 수입니다. 한 마디로 Noise 제거 단계의 수를 결정한다고 보시면 됩니다. 일반적으로 Step의 수가 커질수록 보다 정교한 이미지가 생성되지만, 그만큼 GPU에 부하가 걸리기 쉽고 처리 시간이 증가하게 됩니다. 학습 모델마다 최적화된 Step 수를 권장하고 있으니 모델을 다운 받은 페이지 정보를 확인해 보시길 권장드립니다.
(3). CFG (Classifier Free Guidance)
Cfg는 유저가 CLIP Text Encoder를 통해 입력한 프롬프트의 준수 정도를 의미합니다. 다시 말해, Cfg 값이 높을 수록 유저의 텍스트 프롬프트가 모델 및 이미지 생성에 주는 영향이 커지게 됩니다. 다만 해당 수치가 너무 높게 설정되면 과적합 되어 생성 이미지의 품질이 오히려 저하가 될 수 있습니다. 하여 적당한 수치 5~7 정도의 수치로 설정한 뒤 생성된 이미지 상태를 확인해 보며, 개인 취향에 맞는 최적의 Cfg 값 찾아가시길 권장 드립니다. 참고로 최신 모델일 수록 Cfg 값을 작게 잡는 경향이 있으며, 이는 그만큼 최신 모델의 유저 프롬프트 이해도가 높다는 것을 의미하는 셈입니다.
(4). Sampler
앞서 설명한 Step이 Noise를 제거하는 단계 별 수를 의미했다면, Sampler의 경우, Noise를 제거하는 방법을 의미합니다. 어찌 보면 노이즈를 제거하는 보법(?)이라고도 할 수 있겠습니다. 우리가 흔히 기안 84 씨와 같은 특이한(?) 사람들에게 '보법이 남다르다'라는 표현을 쓰곤 하는데요. 스테이블 디퓨전에서도 Sampler마다의 보법에 따라 다양한 이미지 결과가 나타나곤 합니다. 그래서 유저가 생성하고자 하는 이미지 목적과 특성에 맞는 Sampler 옵션을 선택해야 합니다. Sampler의 종류와 각각의 특징들에 대해서는 다른 콘텐츠에서 정리하여 다루도록 하겠습니다.
Sampler 종류 : Euler, Euler_a, dpm, dpmpp_sde, dpmpp_2m, dpmpp_2m_sde, etc
(5). Scheduler
Scheduler는 Sampler와 한 몸으로 움직이면서 이미지 예측 Noise 제거 과정의 타이밍을 제어하는 역할을 합니다. 마찬가지로 어떤 Scheduler 옵션을 선택하는지에 따라 이미지 생성 속도와 품질에 영향을 미치기 때문에 이 역시 추후 다른 콘텐츠에서 좀 더 자세히 다뤄보도록 하겠습니다.
Schedule 종류 : normal, Karras, sgm_uniform, simple, etc
(6). Denoise
Ksampler 노드에서 반드시 이해하고 넘어가야 할 마지막 파라미터는 바로 Denoise입니다. 앞서 말씀드린 것처럼 스테이블 디퓨전 모델의 이미지 생성 메커니즘의 핵심 축을 차지하고 있기 때문입니다. 이 수치는 Latent Image에 적용할 Noise의 양을 의미하는데 1.00의 수치에 가까울수록 컨디셔닝에 따른 예측 노이즈가 많이 형성되어 보다 정확한 이미지를 생성합니다.

T2I 생성 시에는 무조건 Denoise 수치를 1.00으로 맞추면 되지만, I2I의 경우 적절한 Denoise 수치 조정이 필요합니다. 이와 관련해서는 I2I 이미지 생성 관련 콘텐츠에서 자세히 다루겠습니다. 중요한 것은 보통의 T2I 이미지 생성 시에는 Denoise 값을 1.00으로 설정하여 사용하시면 됩니다.
5. VAE Decode
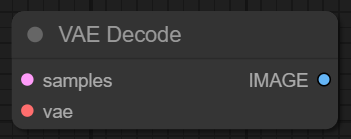
지금까지의 과정을 통해 생성된 이미지는 여전히 우리 눈으로 확인할 수 없는 잠재 공간 속 데이터로 존재하고 있습니다. 하여 이러한 데이터를 사람의 눈으로 식별할 수 있도록 Pixel 단위의 이미지로 변환시켜 주는 것이 바로 VAE Decode 노드입니다. VAE에도 여러 모델이 존재하며 사용하는 체크포인트 모델에 적합한 VAE 모델 선택 및 사용이 필요합니다만, 최근에 학습된 모델의 경우 대개 적합한 VAE 모델이 이미 내재되어 있기 때문에 큰 걱정 안 하셔도 될 것 같습니다. 만일 별도의 VAE 모델 로드가 필요하다면 Load VAE 노드를 활용하여 모델을 불러오고 VAE Decode 입력 단자에 연결해 사용하시면 됩니다.
지금까지 ComfyUI를 사용하는 데 있어 반드시 알아두어야 할 필수 노드들과 특징에 대해 알아보았습니다. 다음 콘텐츠에서는 직접 이미지를 생성해 보면서 노드 연결과 파라미터 수치 조정에 따른 차이점 등을 살펴보도록 하겠습니다.
'AI 제작 > Stable Diffusion' 카테고리의 다른 글
| 스테이블 디퓨전 3 - CKPT 모델 (0) | 2025.02.18 |
|---|---|
| 스테이블 디퓨전 2 - ComfyUI 설치 방법 (2) | 2025.02.17 |
| 스테이블 디퓨전 1 - 작동 원리에 대하여 (2) | 2025.02.17 |